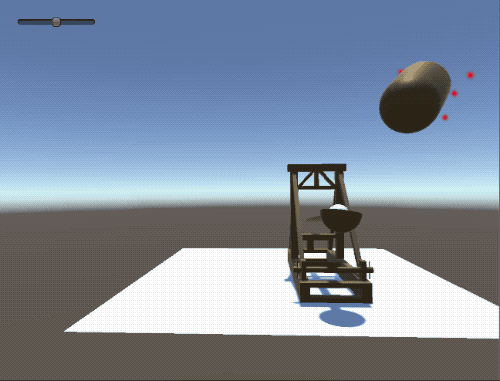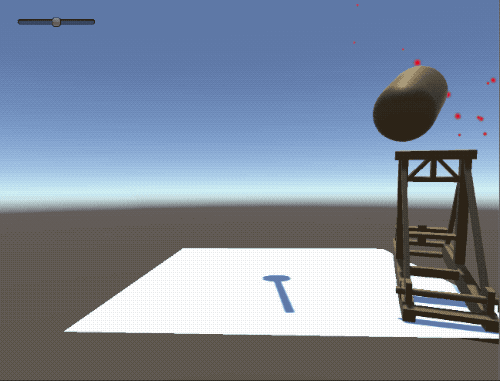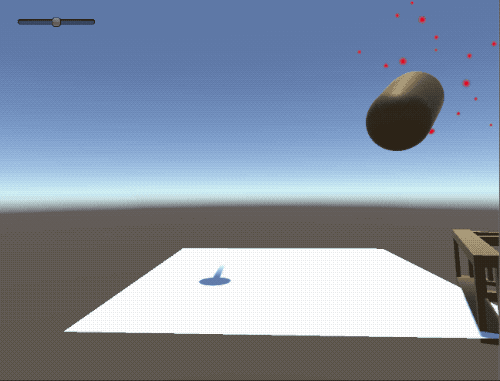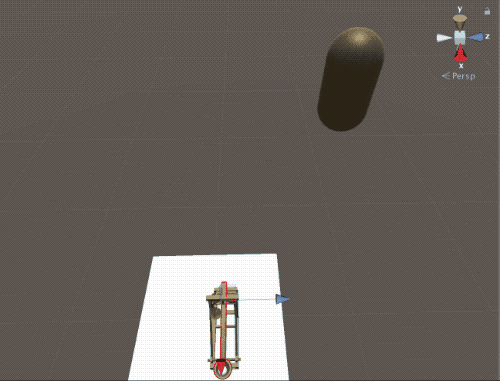
Inspired by both medieval siege engines and the recent release of Unity’s reinforcement learning SDK I taught a catapult to both identify, aim, and destroy a “missile” (in this case, a loving, rendered cylinder). The following post is full of fun gifs of a “brain” firing a catapult as well as some insights I gained while building the project.
 Saving the day one shakily shot sphere at a time
Saving the day one shakily shot sphere at a time
Unity
Unity’s ml-agents SDK was released last week, bringing with it a solid foundation for training agents to act in quasi-realistic environments. Simulation is now, and will be for the foreseeable future, a critical step in teaching robots to work in the real world. The closer a simulation can mimic the environment a robot is expected to encounter the more tractable learning in real world becomes – Unity’s biggest selling point.
Although fresh on the scene – I was constantly diving into the source to figure out yet-to-be documented parts of the SDK and add small features – the power of a more abstracted training environment is made quickly apparent. Rapid switching between player control of an agent and an external TensorFlow brain, adding new inputs like cameras or states with drag and drop, and having a GUI for reviewing how the physics in your scene is playing out are indispensable assets for building complicated environments.
For this project Unity was able to run 1,000,000 trials with an average of ~350 steps per trial in about an hour and a half on my mid 2015 Macbook Pro. It was a reasonable speed for me to iterate on the physics modeling and reward functions without being stuck waiting too long for it to finish, though it indicates for more complicated physics I’ll definitely be upgrading to a more powerful external card.
 What the agent sees while training
What the agent sees while training
Art
Crafting deep reinforcement learning algorithms remains solidly in the “art” side of the “art or science” Venn diagram. While ml-agents comes with an off the shelf SOTA DRL algorithm (PPO), my experience (made concrete in recent papers) of getting the model to train consisted of a lot of haphazard hyperparameter guessing and rerunning with different seeds. This game-of-darts version of building a model 1) makes me want all the gpu and 2) makes one yearn for a more theoretical understanding of machine learning.
The Future
Unity’s making a play here for what will be a large market soon. I have my doubts they’ll succeed in the long run, primarily stemming from how constrained they are as a game engine first and realistic physics simulator second, but their first foray into the space is compelling and I’ll be using it for my next project.
 Physics is hard
Physics is hard